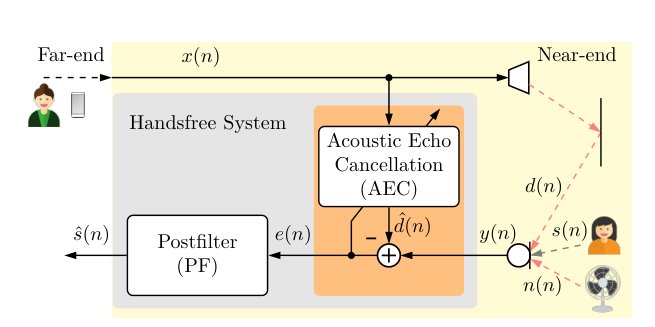
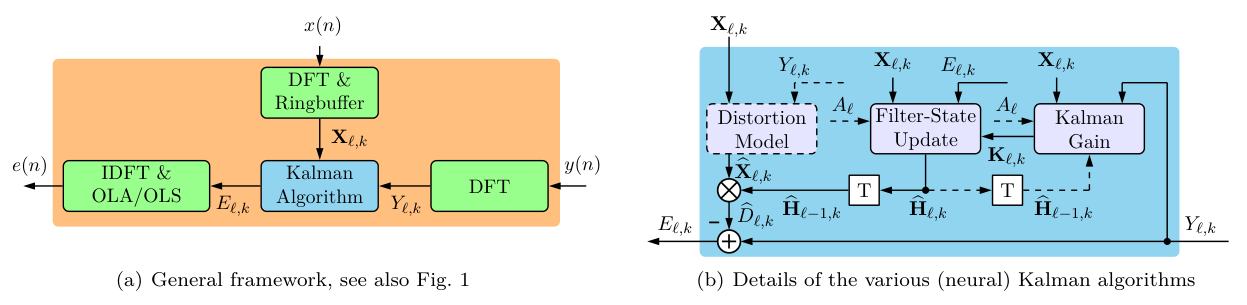
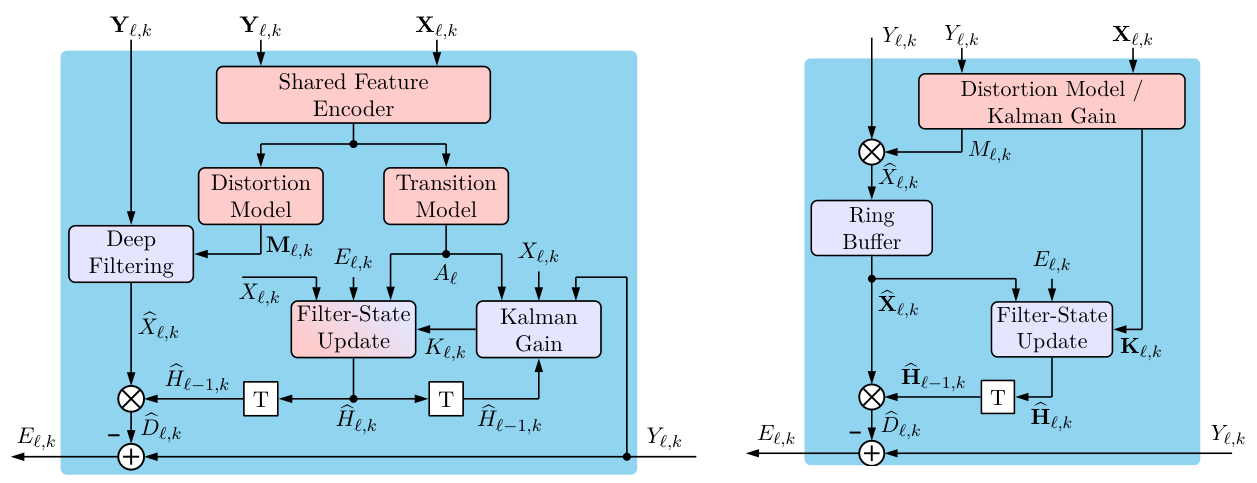
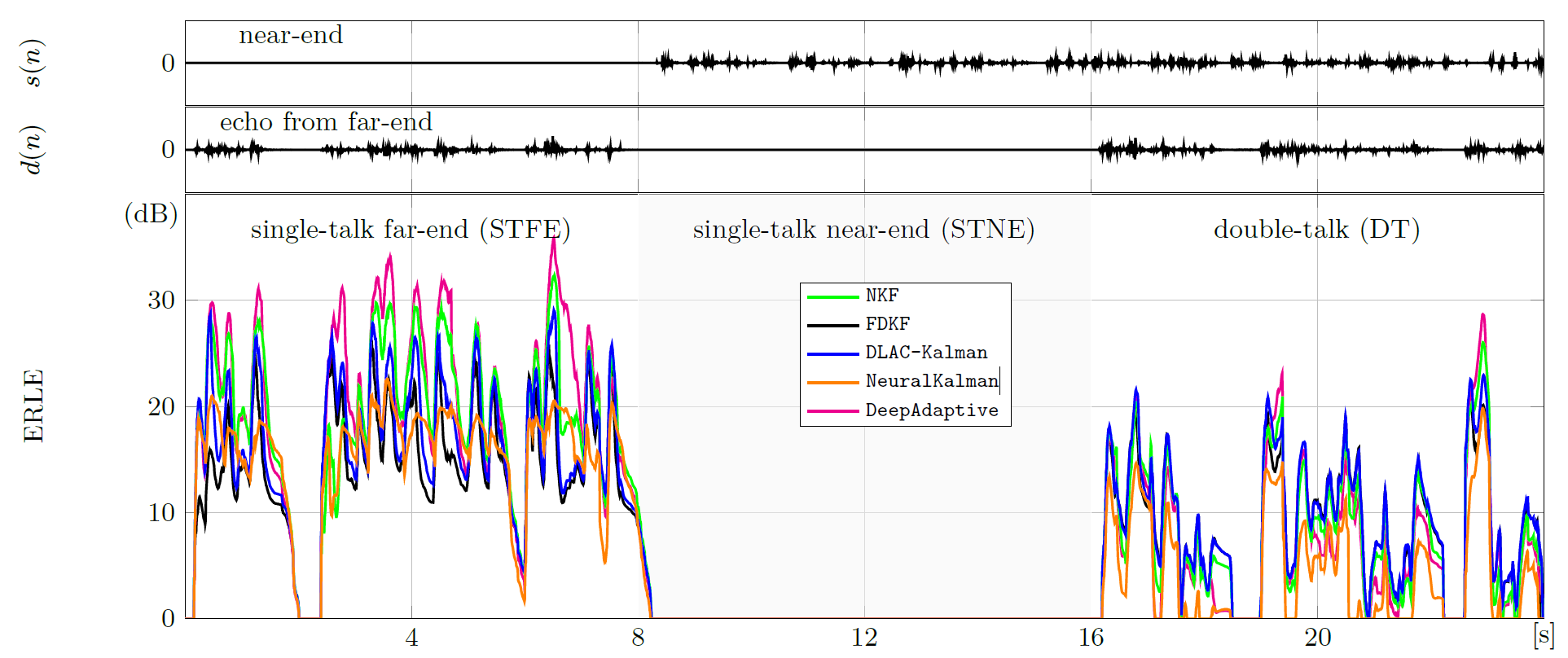
-
The Loop: Far-end speech
x(n)plays through a loudspeaker, travels through the room, and is picked up by the microphone as echo. -
Signal Mixture: The mic signal
y(n) = s(n) + n(n) + d(n), wheres(n)is Near-end speech,n(n)is Background noise, andd(n)is Echo. -
The Goal: Use the reference
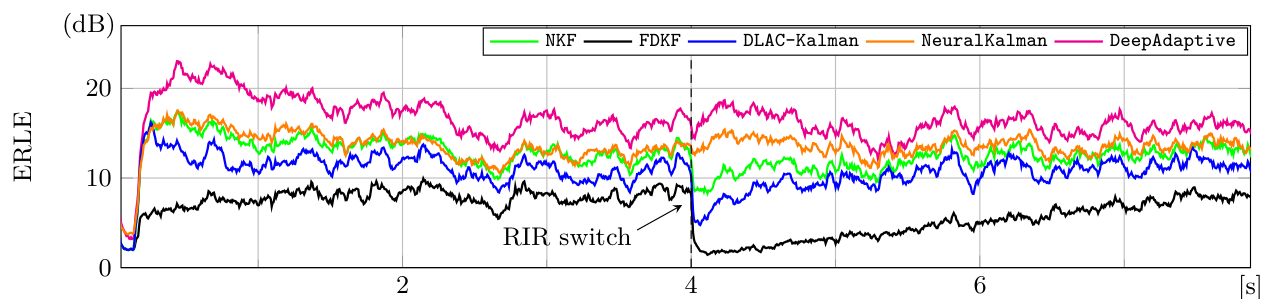
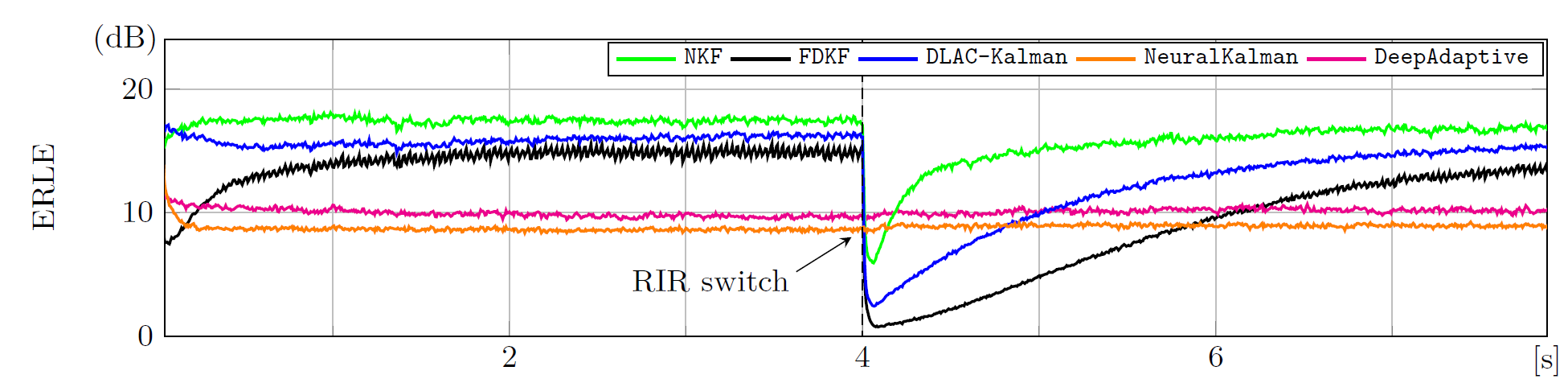
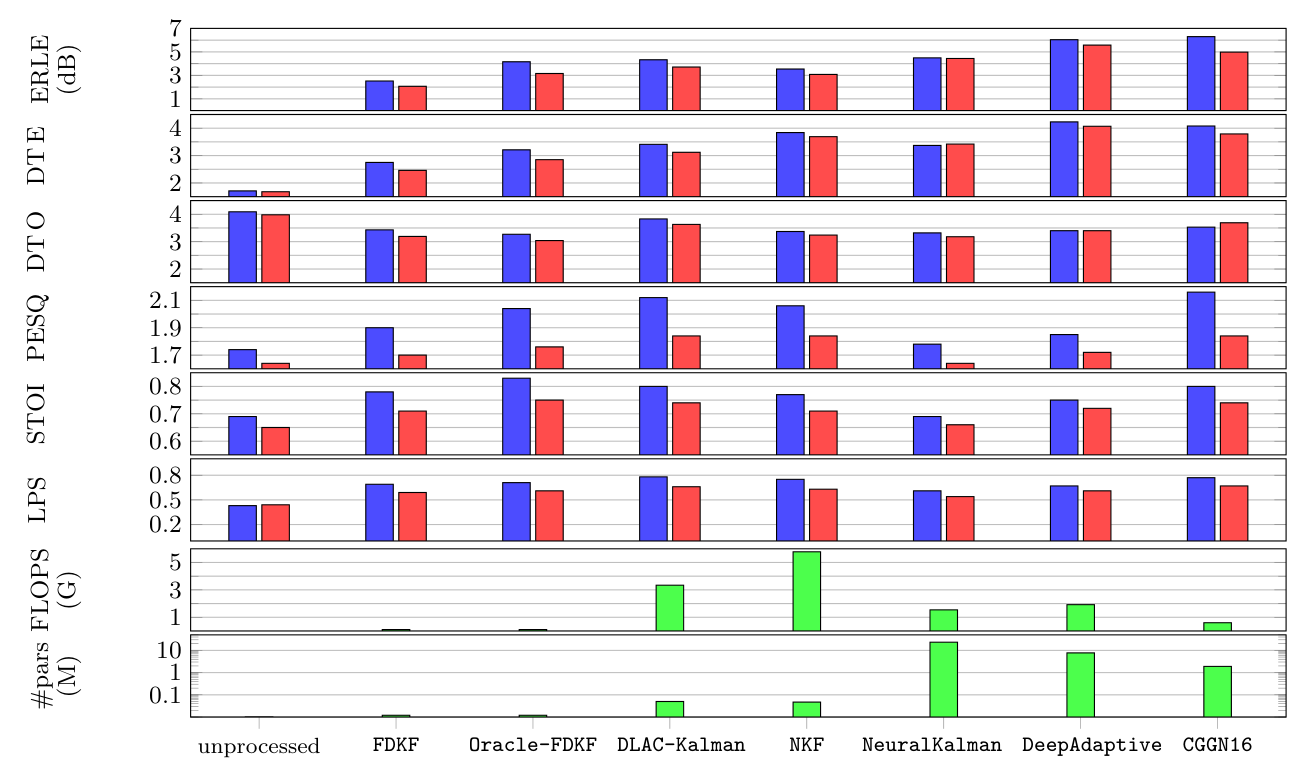
x(n)to estimate and subtract the echo. - The Challenge: It's not just about "lowering volume". During double-talk, the algorithm must suppress echo but preserve near-end speech, and adapt quickly when the echo path changes.